[Deep Learning] XiaoiceSing
서론
SVS 시스템은 음악 악보 정보를 바탕으로 singing voice를 만드는 시스템을 통칭한다. 여기서 singing voice는 보통 가사, 템포, 피치 등을 의미한다. SVS 시스템을 잘 만들기 위해선 다음과 같은 요소를 고려해야한다.
- 명확한 발음, 좋은 음질, 자연스러움을 얻기 위한 spectral feature를 예측할 수 있는 강력한 spectrum model
- singing의 복잡한 f0 contour를 잘 만들어내는 효과적인 F0 model
- singing의 박자요소를 잘 배우는 duration model
기존 SVS 모델은 unit concatenation과 statistical parametric synthesis방식으로 SVS시스템을 만들었지만, 자연스로운 노래 소리와는 거리가 먼 방식이었다.
딥러닝모델이 (FFNN, LSTM 등등) SVS 성능을 향상시키는 방식으로 도입되었다. GAN이 FFNN의 over-smoothing effect를 완화시키는 역할을 하였다.
FFT를 이용한 timbre를 모델링 시 exposure bias issue를 해결하는 능력을 가지고 있었고, CNN을 이용해서 singing voice의 long-term dependency를 잘 모델링하는 모델 또한 나오게 되었다.
그런데 이런 모델들 대부분 spectral feature를 잘 모델링하는데 초점이 맞추어져 있고, F0와 duration으로부터 나오는 dynamic과 리듬적 요소에 대해선 잘 다루지 못하는 것 같다.
F0와 duration을 잘 모델링 하기 위한 몇몇 연구가 제안되었다. F0 모델링 부분에선, note에 대해 예측 F0의 weighted average를 계산하는 방식이 제시되었다. 이 방식의 문제점은 SVS에서의 out-of-tune 문제의 완화가 여전이 어렵다는 것이다. 그리고 후처리 방식은 F0 contour의 dynamic을 smooth할 것이라는 점이고, F0와 spectral feature의 잠재적인 상호관계를 무시한다는 단점이 있다.
duration model에선 musical note의 길이와 predicted duration의 길이를 맞추는 과정이 들어가는데, 한 연구에선 phoneme duration의 합을 post-processing method를 통해 duration prediction의 정규화시킴으로써 total predicted duration을 note duration으로 heuristic하게 맞추었다. 이 연구 또한 모델 자체가 duration을 정확하게 예측하는 것이 중요했다. 게다가 위 연구에선 F0, duration, spectum model이 독립적으로 학습되었어서 singing voice의 일관성과 음악적 요소에 관한 정보가 무시된다는 단점이 있다.
이 연구에서 제시하는 xiaoicesing은 Fast-speech에서 영감을 따오고 약간의 수정을 통해 SVS 모델을 만들었다.
- 가사의 phoneme sequence 뿐만 아니라 note ducation, note pitch와 같은 정보또한 encoding한 후 input으로 제공한다.
- out-of-tune issue문제를 헤결하기 위해 note pitch와 predicted f0 사이에 residual connection을 붙인다.
- phoneme duration loss와 더불어서 syllable duration loss이 학습 과정에서 고려되어서 리듬을 좀 더 살릴 수 있게 하였다.
- Mel spectrogram 대신, Mel-generalized cepstrum (MGC)과 band aperiodicity(BAP)을 모델링하고 WORLD vocoder를 사용하여 singing voice를 합성함으로써 input F0 contour와 generated singing voice의 F0 contour가 일관성을 가질 수 있도록 한다.
Decoder와 duration predictor가 같은 encoder를 공유하는 Fastspeech의 구조를 이용해서 spectrum과 F0, duration model이 같이 학습되게 된다.
Architecture
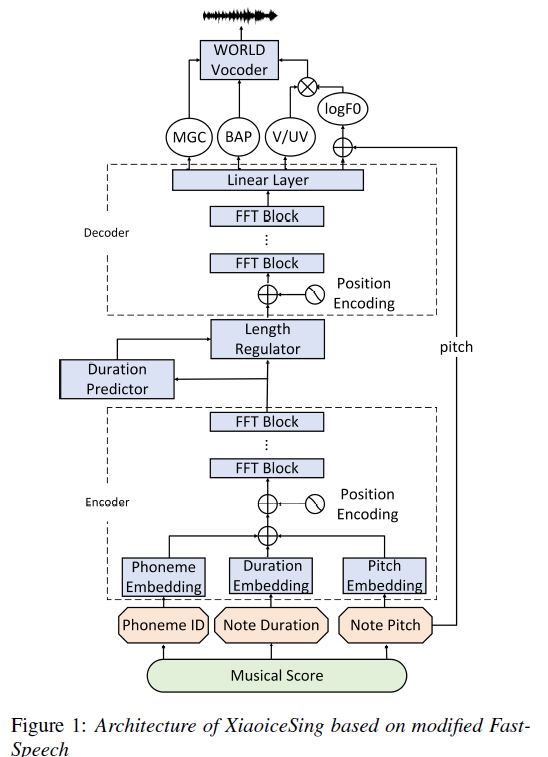
Musical score encoder
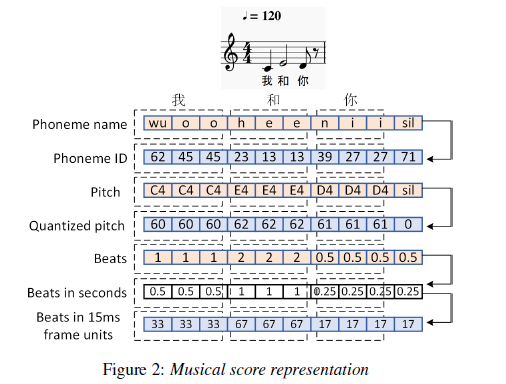
기본적으로 musical score는 가사, note pitch, note duration 등을 포함하고 있다. 맨 첫번째로 가사를 graphme to phoneme conversion을 통해 phoneme sequence로 변환한다. 각 note pitch는 midi standard를 따르는 pitch id로 변환하고, note duration은 music tempo로 quantize하고 frame 수로써 나타내게 된다. 여기서 frame 수는 phoneme frame의 갯수를 뜻하게 된다. note pitch와 note duration정보는 phoneme sequence의 길이만큼 복제되어 맞춰지게 된다. (musical score $S \in R^{N \times 3} $ 여기서 $N$은 phoneme의 갯수를 의미) 각각의 phoneme frame은 phoneme ID와 그에 해당하는 note pitch, duration정보를 포함하게 된다.
각각의 음악 정보(phoneme, note pitch, note duration)는 embedding을 통해 같은 dimension의 vector로 표현되고, positional encoding을 통해 더해지게 된다. 이렇게 만들어진 vector는 여러개의 FFT block으로 이루어진 encoder를 통과하게 된다. (FFT block: self attention network와 2개의 1D convolution network, ReLU 활성화 함수로 이루어진다.)
Duration predictor
Duration predictor는 1개의 1D CNN으로 이루어져 있고 FastSpeech의 length regulator를 지도하기 위해 학습된다. (knowledge distillation) Duration predictor는 spectrum 및 F0 예측과 동일한 인코더 출력을 활용한다.
연구에서는 리듬이 주로 시간적인 순서에 기초한다는 것을 보여주고 있다. phoneme duration와 더불어서, syllable duration또한 SVS의 리듬을 결정짓는데 중요한 요소이다. 따라서 phoneme level duration 뿐만 아니라 syllabel level duration또한 적용해서 리듬적인 패턴을 더욱 잘 파악할 수 있도록 한다. 특히, note는 가사의 syllable과 연관이 되어있다. (하나의 syllable을 발음하기 위해 하나 혹은 여러개의 note가 대응된다.) 따라서 duration predictor loss는 phoneme duration뿐만 아니라 syllable duration도 반영해서 다음과 같이 나타낸다.
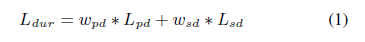
여기서 $L_{bd}$와 $L_{sd}$는 각각 phoneme duration loss와 syllable duration loss를 의미하고, $w_{bd}$와 $w_{sd}$는 각각에 해당하는 가중치를 의미한다.
Decoders
본 연구에선 명시적인 F0 control과 극단적으로 높거나 낮은 음높이를 올바르게 표현할 수 있는 WORLD vocoder가 waveform을 만들기 위해 사용된다. 따라서 decoder는 mel spectrogram 대신 MGC와 BAP를 예측하게 된다.
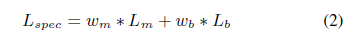
$L_m$, $L_b$, $w_m$, $w_b$는 각각 MGC loss, BAP loss를 의미한다.
Singing 같은 경우는 speech보다 더 정확한 F0 contour를 요구하게 된다. singing의 f0는 80~3400Hz의 넓은 범위를 가지게 되고 vibrato나 overshoot과 같은 F0의 움직임은 감정을 더욱 효과적으로 전달하는데 도움이 된다. (실제로 한 연구에선 일반적인 pitch 에서 조금만 다른 pitch가 전달되면 듣는이의 listening experiment를 많이 해친다고 결론을 내렸다.) 그에 반해 training data만으론 모든 pitch range를 충분하게 반영하기 어렵다. 즉, F0 예측은 input note pitch가 training data에 없거나, 조금밖에 없으면 문제가 발생하게 된다는 것이다. Pitch shift를 통한 Data augmentation을 통해 이런 문제를 어느정도 해결해볼 수 있지만 경제적이지 않고 훈련시간을 더욱 늘리는 원인이 되기도 한다.
이를 대체하기 위해 본 논문에선 residual connection을 제안하게 된다. 여기선 F0의 log scale을 넘겨주게 된다. 이 방식으로 decoder는 standard note pitch로부터 human bias한 부분만 예측하면 되고, 이를 통해 rare하거나 unseen한 데이터에 대해서도 대응을 할 수 있게 된다.
보통 F0 prediction은 V/UV decision을 함께 사용하는 경우가 많다. V/UV decision은 binary이기 때문에 logistic regression이 여기에 적용되게 된다. 결국, Decoder의 loss를 다음과 같이 쓸 수 있다.
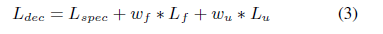
$L_f$, $L_u$는 logF0의 loss와 V/UV decision의 loss를 의미하고, $w_f$, $w_u$는 각각의 가중치를 의미한다. <!–
Experiments
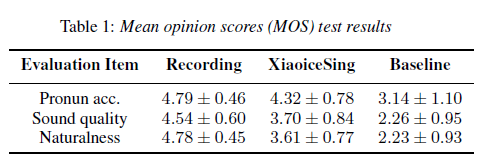
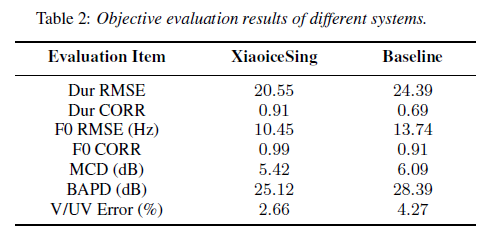
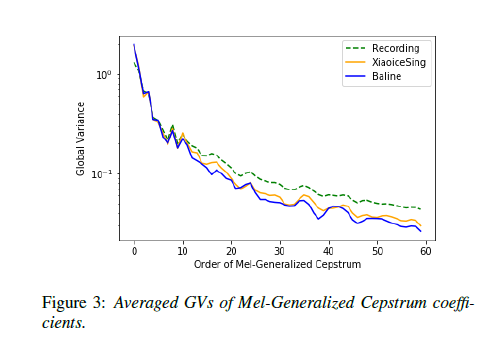
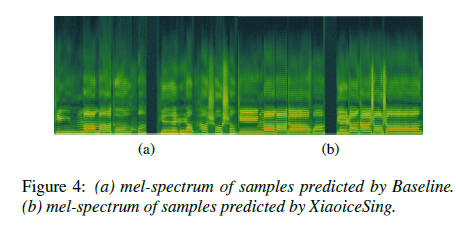
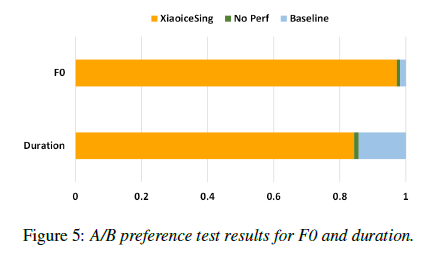
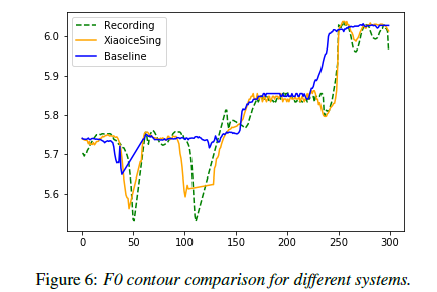
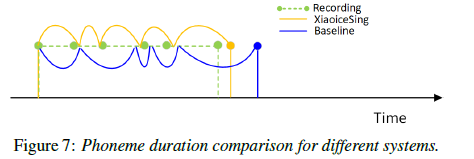
Conclusion
본 논문을 통해서 –>
참고문헌
https://arxiv.org/abs/2006.06261
The posts is for personal study.
If you find some mismatches or errors, please give comments or email to me.
Thank you. :)