[Deep Learning] Conformer
서론
이렇게 초안만 잔뜩 쌓이고 블로그 글을 못 올리는건 별로 안좋은거 같은데… 오늘은 트렌스포머를 이용하여 딥러닝 모델의 음성인식 성능을 높여준 구조인 컨포머(conformer)에 대해 알아보자.
이 구조는 음성인식을 위해 처음 도입되었지만, 현재 회사에서 개발중인 SVS 시스템에서 transformer 대신에 들어간 것을 보니, 다양한 분야에서 사용할 수 있을 것 같다.
개요
convolution과 self-attention을 결합하여 사용한 모델이 독립적으로 사용한 모델보다 더 좋은 성능을 보인다. 같이 학습하면 local 정보하고 global 정보 둘 다 학습할 수 있다는 것이다.
이 논문에선 convolution과 self attention을 유기적으로 결합하여 global과 local 정보를 효율적으로 학습할 수 있는 방법을 제시한다! self attention이 global interaction을 학습하고 convolution이 local한 corretlation을 학습할 수 있는 구조인 것이다.
어텐션 헤드 숫자, convolution 커널 크기, 활성화 함수 종류, feed forward layer의 종류를 비교해봄으로써 어떤 친구가 가장 정확도 향상이 있었는지 확인한다.
Conformer Encoder
input에 convolution을 적용하여 subsampling한 다음, comformer block들을 달아둔다.
- Comformer block: (feed-forward module) - (self-attention module) - (convolution module) - (feed-forward module) - (layer norm)
각각의 모듈에서 residual을 적용한다.
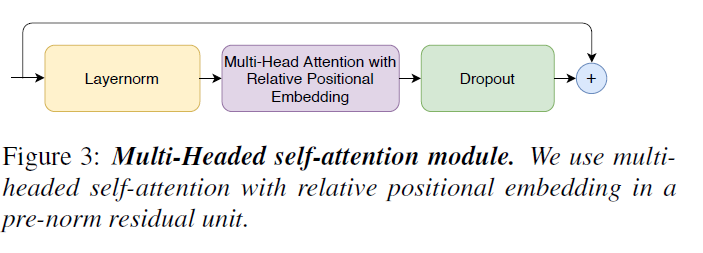
Multi-Headed Self-Attention Module
- Multi-headed self-attention module: (layer-norm) - (Multi head attention with Relative Positional Encoidng) - (Dropout) - (Residual)
Transformer-XL 로부터 relative sinusoidal positional encoding을 가져왔다고 한다. 이 positional encoding 방식이 self-attention module을 다양한 길이의 input을 잘 일반화하고 다양한 길이의 utterance에 대응을 더 잘 한다고 한다.
 |
|---|
| (Conformer 논문) |
- relative sinusoidal positional encoding: 추후 설명
Convolution module
-
Convolution module: (Layernorm) - (Positionwise Conv) - (GLU activation) - (1D depthwise conv) - (BatchNorm) - (Swish Activation) - (Positiwise Conv) - (Dropout) - (Residual)
-
GLU: (대충 설명 들어갈 자리)
gating mechanism으로 시작한다. 즉, position-wise convolution and Gated liner unit (GLU). 이후에 1D conv layer와 batch-norm 등장
Feed forward module
- Feed forward module: (Layernorm) - (Linear) - (Swish Activation) - (Dropout) - (Linear) - (Dropout) - (Residual)
Attention is all you need (Transformer) 와 동일.
Conformer block
conformer block은 multi-head self-attention module과 convolution module을 감싸는 2개의 feed forward module로 구성되어 있음. Macaron-Net에서 처럼 각 feed-forward module의 반만큼을 적용한다.
(대충 수식 적혀있는 그림 첨부)
논문에선 예비 실험을 통해 feed forward module 하나만을 사용하는 것 보다 가중치를 반으로 둔 feed forward module을 감싼 것이 더 좋은 성능을 보인다는 것을 확인했다.
Experiments
Data
- LibriSpeech
- 970 시간의 labeled speech
- Language model 구축을 위한 추가적인 800M word token text-only corpus
- window size: 25ms, stride: 10ms
Ablation Studies
Conformer block vs Transformer block
- 같은 parameter 갯수를 가진 Conformer block과 Transformer block을 비교해보았다.
- Conformer는 안에 추가적으로 convolution sub-block이 들어있다는 점이 가장 큰 차이점
- FFN을 하나만 쓰는 것보다 Macaron-Net 스타일의 FFN (가중치를 반으로 둔 두개의 FFN으로 블럭을 감싸는 것)이 더 효과적.
- Conformer에서 사용한 Switch Activation이 더욱 빠른 최적점 수렴에 영향을 준다.
(표 삽입)
Combinations of Convolution and Transformer Modules
- MHSA module과 convolution을 연결하는 다양한 방법을 연구해보았다
- Depthwise convolution을 lightweight convolution으로 대체했을 때 성능 저하 발생
- Convolution module을 MHSA module 앞에 넣었더니 약간의 성능 저하 발생
- Parallel MHSA 및 그 결과를 concat한 것을 convolution에 넣었을 때 성능저하 발생
(표 삽입)
Macaron Feed Forward Modules
- Macaron Feed forward module의 유무에 대한 실험 실시
- Macaron Feed forward 대신 single FFN을 사용했을 때 성능저하 발생
- half step 대신 full step 으로 계산했을 대 성능저하 발생
(표 삽입)
Number of attention heads
self attention에서 각 attention head가 input의 다른 부분들을 학습하기 때문에 단일 attention보다 예측향상할 수 있다. 여기서는 모든 layer의 head의 갯수를 4에서 32개로 설정하여 실험한다. 실험결과 16개일때 가장 좋은 예측결과임을 보였다.
(표 삽입)
Convolution kernel size
커널 크기 [3, 7, 17, 32, 65]에서 비교했을 때 17에서 32까지 올릴 때 성능 향상이 있었지만 65부턴 성능이 하락했다. 소수점 2자리 수까지 비교해보았을 때, 커널 크기 32가 가장 좋은 성능을 보였음.
(표 삽입)
참고문헌
https://arxiv.org/abs/2005.08100
The posts is for personal study.
If you find some mismatches or errors, please give comments or email to me.
Thank you. :)